-
이상치 아웃라이어 Outlier 전처리 (ft. load_wine 와인 데이터셋 불러오기)데이터 분석 공부/파이썬 데이터 분석 2024. 4. 26. 14:01728x90
사이킷 런 패키지 안에 포함되어 있을 정도로 유명한 와인 데이터 셋을 가지고 실습을 했다.
다만 데이터가 데이터프레임 형식으로 불러와지는 것이 아니기 때문에,
wine_load.data , wind_load.feature_names 를 선택해서 데이터프레임화 해 주어야 한다!
from sklearn.datasets import load_wine wine_load = load_wine() wine = pd.DataFrame(wine_load.data, columns=wine_load.feature_names)그리고 아웃라이어 실습만 할 거라면 굳이 필요 없지만,
y값(정답값, 타겟값)에 해당하는 wine.target 을 가져와서 컬럼에 붙여주는 방법도 배웠다.
# 1단계 # 타겟값 확인 -> 0, 1, 2 다중 분류 wine_load.target # 2단계 # assign 함수로 마지막 컬럼에 추가하기 wine2 = wine.assign(Class = wine_load.target) # assign 함수 대신 그냥 변수명에 할당하는 방법도 있음 wine['Class'] = wine_load.target # 3단계 # map 함수를 이용해 0,1,2로 이루어진 Class를 일괄적으로 변경해줌 wine['Class'] = wine['Class'].map({0 : 'class_0', 1 : 'class_1', 2 : 'class_2'}) # 혹은 2,3단계를 아래와 같이 한번에 진행해 줄 수도 있다. wine['Class'] = list(map(lambda x : {0 : 'class_0', 1 : 'class_1', 2: 'class_2'}[x], wine.target))아웃라이어는 정상 범주 밖에 있는 이상치를 의미한다.
박스플롯으로 시각화 해 보면 값의 분포 및 아웃라이어 확인을 쉽게 할 수 있다.
import matplotlib.pyplot as plt plt.boxplot(wine['color_intensity'], whis=1.5) plt.title('color_intensity')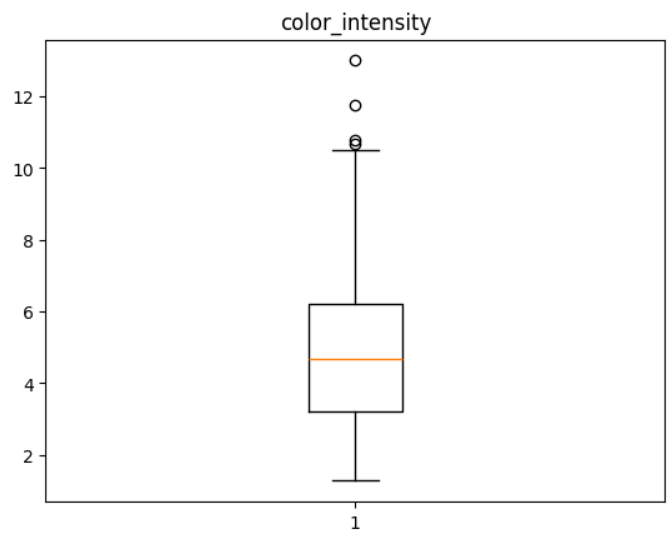
기본적인 이상치 범위를 설정하는 함수는 아래와 같다.
1~3분위 사이의 값을 IQR이라고 하고,
1분위 값 - 1.5IQR ~ 3분위 값 + 1.5IQR 사이에 들어오는 값이 아니면 이상치로 판단한다.
import numpy as np def outliers_iqr(dt, col): quartile_1, quartile_3 = np.percentile(dt[col], [25, 75]) iqr = quartile_3 - quartile_1 lower_whis = quartile_1 - (iqr * 1.5) upper_whis = quartile_3 + (iqr * 1.5 outliers = dt[(dt[col] > upper_whis) | (dt[col] < lower_whis)] # 비트 연산자 | (or을 의미) 사용해야 함에 주의1 return outliers[[col]]위 함수의 결과로 아웃라이어에 해당하는 값들만 뽑아낼 수 있게 된다.
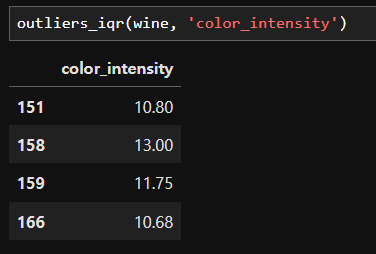
이 행들을 아래 코드를 통해 drop 해 줄 수 있다.
# drop 함수에서 axis 설정하지 않으면 행(row) 지우는 것이 디폴트 # index를 활용해서 아웃라이어 행 drop wine_outliers = wine.drop(index=outliers_iqr(wine, 'color_intensity').index)이렇게 바로 아웃라이어 데이터를 제거할 수도 있지만,
데이터 양이 충분하지 않는 경우 등 아웃라이어를 삭제하지 않고 대체하는 방법도 있다.
# 아웃라이어를 포함한 평균치를 대입 wine['color_intensity'] = wine['color_intensity'].fillna(wine['color_intensity'].mean()) # 아웃라이어를 제외한 평균치를 대입 # 아웃라이어를 결측치로 바꾼 다음 평균을 구한 뒤, 해당 평균으로 아웃라이어를 대체 wine.loc[outliers_iqr(wine, 'color_intensity').index, 'color_intensity'] = np.NaN wine['color_intensity'] = wine['color_intensity'].fillna(wine['color_intensity'].mean())'데이터 분석 공부 > 파이썬 데이터 분석' 카테고리의 다른 글
로깅 logging 시스템 생성 , 로그 메시지 기록하기 (0) 2024.05.10 시계열 분석에서 자주 쓰는 판다스 기초 함수 (0) 2024.04.26 Python matplotlib 파이썬 시각화 한글 폰트 깨질 때 (하라는 대로 다 했는데도 안 될 때! cache 파일을 삭제하세요) (0) 2024.04.19 플레이데이터 데이터 엔지니어링 31기 3주차 회고 (1) 2024.04.19 git 으로 팀 프로젝트하기 - add, commit, push, checkout, status (0) 2024.04.18