-
스포츠 데이터 파이썬 크롤링 -Selenium, By.CSS_SELECTOR, pickle데이터 분석 공부/파이썬 데이터 분석 2024. 4. 6. 21:10728x90
셀레니움(Selenium)과 뷰티풀수프(BeautifulSoup)를 활용해서 스포츠 선수들의 정보를 크롤링 해 보겠습니다.
우선 몇 가지 함께 알아두면 재밌는 정보가 있어서 함께 정리해 둡니다.
#crontab -e리눅스와 유닉스 기반 시스템에서 주기적으로 작업을 실행하기 위해 사용되는 명령어입니다. 'cron'은 리눅스 시스템에서 스케줄링 작업을 관리하는 시스템이며, crontab 명령어를 사용하여 사용자의 cron 작업을 관리할 수 있습니다.
crontab -e 명령어는 현재 사용자의 cron 작업을 편집하기 위해 텍스트 에디터를 열어줍니다. 사용자가 이 명령어를 실행하면 텍스트 에디터가 열리고, 해당 사용자의 cron 작업을 정의하는 텍스트 파일이 표시됩니다. 사용자는 이 파일에 주기적으로 실행하길 원하는 명령어를 추가하고, 저장한 후 에디터를 닫으면 해당 cron 작업이 스케줄에 추가됩니다.
cron 작업은 시간, 날짜 및 실행 주기를 지정하여 실행되며, 예를 들어 매일, 매주, 매월, 또는 특정 시간에 실행되도록 할 수 있습니다. 이를 통해 자동으로 시스템 유지보수, 백업, 데이터 처리 등을 수행할 수 있습니다.
# kafka
자료구조 중 que의 일종입니다.
지난 포스트에서 종목정보 가져오기 위해 naver와 KRX에 명령어를 보냈고 정상적으로 정보가 가져와졌는데요.그걸 요청한 주문서를 kafka
리스트에 이름 쓰는 거 = buffer 버퍼# IP
- private ip : 192로 시작하는 ip 주소. 내부 네트워크에서 쓰는 주소.
공유기나 내부 네트워크를 사용해서 인터넷에 접속할 경우 사설 IP(Private IP)라고 하는 특정 주소 범위(192.168.0.1 ~ 192.168.255.254)가 내부적으로 사용되며, 이걸 알려줘도 외부에서 내 컴퓨터 찾을 수 없음. public ip를 줘야 알 수 있음.- public ip : 외부에서 접속할 때 필요한 고유한 주소.
공유기의 포트 포워딩을 통해 public ip 포워딩해주면 원격으로 사용 가능
ip a
: ip 목록 보여주는 명령어ping 8.8.8.8
ping -c 3 8.8.8.8 (3개만 찍어줘)
: 네트워크 작업 시, 상대방 컴퓨터 네트워크가 살아있는지 확인하는 명령어
: ms(밀리세컨드) 숫자가 작을 수록 좋음
: 8.8.8.8 은 구글의 DNS 서버# 네트워크 환경 체크
# 네트워크 프로그램 설치
(sudo) apt install net-tools
# 현재 사용중인 포트 확인 가능. 안 쓰는 포트는 닫아두어야 해킹으로부터 안전.
netstat -ntlp# 현재 주피터 노트북이 켜져 있는지 확인하는 코드. 내가 알고 싶은 포트(8888)이 있는지 검색(grep) 해서 | (파이프) 로 명령어 전달
netstat -ntlp | grep 8888[포트넘버]
자 이제 본격적으로 셀레니움을 활용하기 위한 환경 설정부터 해 보겠습니다.
# wget : 인터넷에 있는 파일을 다운로드 받는 명령어
향후 스파크, 하둡 등을 다운로드 받을 때 이 명령어를 쓰면 됩니다.
셀레니움을 실행했을 때 크롬을 열 수 있어야 하기 때문에,
크롬 파일을 환경에 다운로드 받는 아래 명령어를 실행할게요.
# 크롬 설치 파일 다운로드 wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb # 크롬 설치 (sudo) apt install ./google-chrome-stable_current_amd64.deb -y크롬 다운로드를 완료했다면 이제 주피터 노트북 환경에서 셀레니움을 실행해볼게요.
driver_version 다음에는 실행하시는 당시의 환경의 크롬 버전을 확인한 다음 해당 버전을 넣어주셔야 합니다.
# 셀레니움 실행하기 google-chrome --version # 현재 설치된 크롬 버전 확인 from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.chrome.service import Service driver = webdriver.Chrome(service=Service(ChromeDriverManager(driver_version="123.0.6312.105").install()))# 원하는 영역의 css 정보 복사하기
F12 (개발자도구) > 선택 원하는 영역 찾아서 우클릭 > copy > copy selector 하면 #lnb > li:nth-child(3) > a 복사됨
이런 정보를 클릭할 건지 (click) , 텍스트를 넣을 건지 (send) 등 코딩하여 자동화가 가능합니다.기존에 우분투 서버에서 설치한 주피터 노트북에서 오류가 발생해 오류 원인 확인, 차선책으로 미니콘다 설치를 했습니다.
더보기오류 원인을 확인해 보았는데
## 오류 발생, 크롬 설치 불가
# 실행되고 있는 실행파일의 위치 확인 : which
which google-chrome # 터미널에 입력하여 구글 크롬 설치 파일 위치 확인
cd /opt/google/ # 들어가서 실행파일 제대로 있는지 확인
## 미니콘다 설치 및 콘다로 가상환경 만들기
conda create --name[이름] --python[버전]
ex) conda create --name encore_py39 python=3.9
conda activate encore_py39 # conda 가상환경 실행하기
conda install jupyter # 콘다 명령어로 주피터 설치해보기
pip install selenium webdriver_manager이제 진짜로 크롤링 코드를 시작합니다...!
우선 선수 고유번호를 가져오기 위해 KBO 홈페이지 내 팀명 선택, 페이지 클릭해 선수 정보를 수집하는 코드를 작성합니다.
# URL 열기 driver.get("https://www.koreabaseball.com/") from selenium.webdriver.common.by import By driver.find_element(By.CSS_SELECTOR, "#lnb > li:nth-child(3) > a").click() driver.page_source driver.find_element(By.CSS_SELECTOR, "#cphContents_cphContents_cphContents_ddlTeam > option:nth-child(3)").click()위 코드에서는 By.CSS_SELECTOR 를 사용했지만, x_path 등 다른 방식으로도 element를 찾을 수 있습니다.
import time import re pattern = re.compile("playerId=([0-9]+)") select_page = "#cphContents_cphContents_cphContents_ucPager_btnNo{}" select_team = "#cphContents_cphContents_cphContents_ddlTeam > option:nth-child({})" playid = [] for x in range(2,12): for_1 = select_team.format(x) driver.find_element(By.CSS_SELECTOR, for_1).click() time.sleep(2) #playid.extend(pattern.findall(driver.page_source)) for y in range(1,6): f2 = select_page.format(y) try: driver.find_element(By.CSS_SELECTOR, f2).click() time.sleep(1) playid.extend(pattern.findall(driver.page_source)) except Exception as e: print ("page 없음 ") time.sleep(2)KBO의 팀 정보를 확인했을 때, 각 CSS 코드 내 번호가 3번부터 11번까지여서 range는 (2,12)로 설정했습니다.
select_page, select_team 에 대한 css 코드를 미리 작성해두고 for문을 돌며 정보를 가져오게 합니다.
끝 페이지까지 모두 수집되면 프린트문과 함께 코드 실행이 종료되도록 했습니다.
import pickle # binary save , load with open("./kbo.pkl", "wb") as f: pickle.dump(playid, f) import pickle with open("./kbo.pkl", "rb") as f: abc = pickle.load(f)피클 형식으로 저장한 이유는 csv, txt 파일 등에 비해 파이썬 환경에서 매우 효율적이고 빠르게 파일을 저장, 불러올 수 있는 형식이기 때문입니다.
자세한 피클 형식의 이점은 아래에 기재해 둘게요.
더보기- 유연성: pickle은 Python 객체의 직렬화에 특화되어 있습니다. 이는 거의 모든 종류의 Python 객체를 저장하고 복원할 수 있음을 의미합니다. 이는 리스트, 딕셔너리, 클래스 인스턴스 등과 같은 복잡한 데이터 구조를 손쉽게 저장하고 다시 로드할 수 있음을 의미합니다.
- 속도: pickle은 데이터를 이진 형식으로 직렬화하기 때문에 일반적으로 텍스트 파일 형식보다 빠르고 효율적입니다. 이는 특히 큰 데이터 세트의 경우에 더욱 두드러집니다.
- 파이썬 전용: pickle은 Python에 특화된 형식이기 때문에 Python 프로그램 간에 데이터를 공유할 때 유용합니다. 다른 프로그래밍 언어와 호환되는 CSV나 JSON과 달리, pickle은 Python에서만 사용할 수 있습니다.
- 구조 보존: pickle은 객체의 구조를 완벽하게 보존합니다. 이는 객체의 계층 구조, 참조, 메소드 등을 유지하며 객체를 저장하고 로드할 수 있다는 것을 의미합니다. 이는 데이터를 다시 로드할 때 데이터의 일관성과 유효성을 보장합니다.
from bs4 import BeautifulSoup as BS import requests import os import re # 선수 고유번호를 넣어 각 URL에 접속해 텍스트 정보 수집 play_url = "https://www.koreabaseball.com/Record/Player/PitcherDetail/Basic.aspx?playerId={}" for x in playid: print(play_url.format(x)) kbo_r = requests.get(play_url.format(x))선수 고유번호를 playid에 모두 수집했으니, 이를 활용해 각 선수들의 프로필 URL에 접속해 정보를 크롤링 할게요.
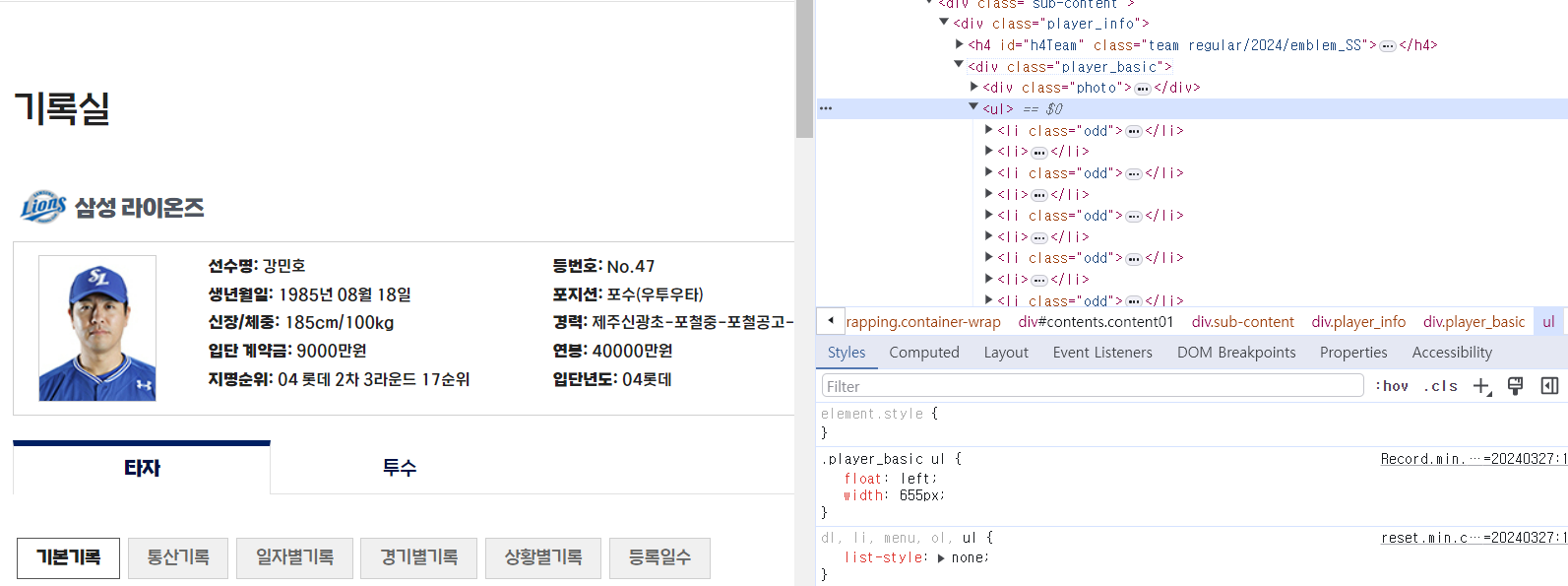
# 위에서 수집한 텍스트들 중 원하는 부분을 찾기 (개인 프로필) # for문 돌며 마지막 선수에 대한 정보를 테스트로 출력 bs = BS(kbo_r.text) for x in bs.find("div", class_= "player_basic").findAll("li"): y= x.text.split(":") y[1] = x.text.split(":")[1].strip() print(y) # dict comprehension # 구단 정보도 별도로 추가하여 df의 신규 컬럼으로 생성 data = {x.text.split(":")[0] : x.text.split(":")[1] for x in bs.find("div", class_= "player_basic").findAll("li")} data['team'] = bs.find("h4", id="h4Team").text data개발자 도구를 활용해, 원하는 정보가 들어있는 곳의 객체와 class 등을 확인해요.
<div class="player_basic"> 이 제가 원하는 정보들이 들어있는 영역이고,
텍스트 데이터들은 <li class> 로 구성되어 있는 걸 확인하여 findAll 메서드로 x 라는 변수에 넣어줍니다.
이 x를 살펴보면 선수명: 강민호 이런 식으로 : 을 통해 데이터를 구분지을 수 있어요.
: 를 기준으로 텍스트를 split 해 주고 y 값에 넣어줄게요.
아래는 사용자 정의 함수로 똑같이 구현해 본 코드입니다.
# 사용자 정의 함수로도 똑같이 구현 def get_kbo(id_): kbo_r = requests.get(play_url.format(id_)) bs = BS(kbo_r.text) data = {x.text.split(":")[0] : x.text.split(":")[1] for x in bs.find("div", class_= "player_basic").findAll("li")} data['team'] = bs.find("h4", id="h4Team").text return data'데이터 분석 공부 > 파이썬 데이터 분석' 카테고리의 다른 글
pandas 데이터 전처리 : 중복값 제거(duplicated), 행열 재구조화(melt) (0) 2024.04.11 파이썬 판다스(Pandas) 자주 쓰는 함수, 기능 연습 (0) 2024.04.11 판다스 pandas 기초개념 : iloc, loc 비교, 데이터 형식 (numpy, series, dataframe) (1) 2024.04.03 파이썬 크롤링 기초 ㅡ Selenium과 BeautifulSoup 차이 (0) 2024.04.03 리눅스 기초 명령어 : ps -ef, |, grep, &, 가상환경, virtualenv, requirements, nohup (1) 2024.04.03 - 유연성: pickle은 Python 객체의 직렬화에 특화되어 있습니다. 이는 거의 모든 종류의 Python 객체를 저장하고 복원할 수 있음을 의미합니다. 이는 리스트, 딕셔너리, 클래스 인스턴스 등과 같은 복잡한 데이터 구조를 손쉽게 저장하고 다시 로드할 수 있음을 의미합니다.